-
Categoria: Esami
-
Pubblicato: Mercoledì, 28 Marzo 2012 05:29
-
Visite: 33747
-
Stampa
-
Email
L’elettroglottografia o elettrolaringografia (EGG) è una tecnica di indagine della funzione glottica introdotta nel 1957 da Philippe Fabre, professore di fisica biologica all’Università di Lille. Essa consente di studiare e monitorare le caratteristiche e la regolarità della vibrazione delle corde vocali senza interferire con l’attività fono-articolatoria e senza arrecare alcun disagio al soggetto in esame. Questa metodica comporta il posizionamento di due elettrodi metallici a placca con superficie di contatto di circa 2-3 cm2 sulla cute di ciascun lato del collo, in corrispondenza delle cartilagini tiroidee a livello del piano glottico, per misurare l’impedenza elettrica che è in funzione del tasso di contatto delle corde vocali (essa diminuisce a corde vocali chiuse ed aumenta a corde vocali aperte); si utilizza una corrente alternata ad alta frequenza (0,3-5 MHZ) ed a bassa intensità (< 20 mA) che non viene avvertita dal paziente e non determina contrazioni muscolari o stimolazioni nervose. Alcuni fattori (tessuto adiposo, spessore della cute e delle lamine tiroidee, movimenti della laringe) possono influenzare il segnale ma i moderni elettroglottografi sono dotati di filtri e di sistemi di controllo automatico dell’amplificazione così da ottenere una stabilizzazione dell’ampiezza della curva EGG. Il segnale elettroglottografico viene visualizzato sullo schermo di un oscilloscopio e registrato per lo studio in tempo differito e per l’archiviazione; attualmente, con la disponibilità di sistemi informatici, il segnale viene acquisito sotto forma numerica, digitalizzando cioè direttamente l’uscita dell’elettroglottografo e memorizzando i dati su hard disk e/o su Cd Rom. In questo modo si evitano tutti i problemi di distorsione di ampiezza e di fase presenti nella registrazione analogica. Esso può essere visualizzato secondo due polarità alternative (in alto la fase di chiusura ed in basso la fase di apertura oppure nella parte superiore la fase di massima impedenza che corrisponde alle corde vocali aperte ed inferiormente la massima ammettenza). L’immagine elettroglottografica appare sotto forma di onda periodica paratriangolare la cui frequenza è uguale alla frequenza di vibrazione delle corde vocali; essa può essere suddivisa in una fase di rapida salita (le c.v. si stanno accollando sul piano orizzontale in senso antero-posteriore), fase quasi statica superiore (fase di massimo contatto), fase lenta di discesa (le c.v. iniziano a separarsi), fase quasi statica inferiore (le c.v. sono separate).Numerosi sono stati i tentativi di classificazione dei tracciati EGG negli ultimi 35 anni. Una modalità di interpretazione e di utilizzo è quella esclusivamente morfologica che cerca di trovare correlazioni fra la forma dell’onda e/o la tipologia della irregolarità nella successione delle onde nel tracciato e particolari situazioni patologiche organiche e/o funzionali. È però opportuno sottolineare che esistono variazioni elettroglottografiche intraindividuali in condizioni fisiologiche, come ad esempio nel passaggio da un registro di petto a un registro di falsetto oppure durante il periodo della muta vocale 4, e che è possibile rilevare una curva EGG anomala sia nei soggetti normali, sia in patologie non strettamente vocali. Si è cercato, quindi, da un lato di parametrare la morfologia del tracciato alla fisiologia della vibrazione mediante correlazioni fra EGG e stroboscopia ed EGG e cinematografia ultrarapida, dall’altro di quantizzare le varie fasi del tracciato essenzialmente sulla coordinata orizzontale e di ottenere una sua normalizzazione che consentisse di eliminare le diversità legate alle variazioni interindividuali o intraindividuali della frequenza fondamentale. Una delle parametrizzazioni morfologiche più complete è quella di Lecluse 24 (Fig. 1) che individua cinque punti significativi nella curva: I: momento iniziale di chiusura; II: momento di chiusura completa solo sul piano orizzontale; III: momento di chiusura completa anche sul piano verticale; IV: momento di inizio dell’apertura; V: momento in cui si realizza l’apertura completa sul piano verticale. Ne conseguono 6 parametri temporali (I-II, II-III, III-IV, IV-V, V-I) che possono essere normalizzati mediante il rapporto fra la loro durata e la durata totale del ciclo elettroglottografico (T). Ferrero propone una semplificazione considerando il periodo I-III (fase di chiusura o di adduzione), il periodo III-V (fase di diastasi o di abduzione), il periodo V-I (fase di apertura) ed il loro rapporto con T dà origine rispettivamente al quoziente di chiusura, al quoziente di diastasi e al quoziente di apertura.

L’elettroglottografia è senz’altro una metodica di esame semplice e non invasiva, che fornisce una esatta misurazione della frequenza fondamentale. È stata utilizzata nello studio di varie laringopatie ma l’applicazione clinica risulta complessa perché non riesce a dare sempre informazioni utili a scopo diagnostico. Alcuni aspetti tecnici dovranno essere risolti ed ulteriori ricerche sono necessarie per superare le controversie relative all’interpretazione e alla quantificazione del tracciato. L’analisi aerodinamica della fonazione trova il presupposto nell’intima connessione anatomo-funzionale della laringe con l’apparato broncopolmonare (mantice) che giustifica l’attenzione che gli Autori hanno sempre rivolto alla dinamica respiratoria in rapporto con il fenomeno della fonazione. I quattro aspetti aerodinamici fondamentali sono: la velocità del flusso di aria a livello della glottide, la pressione sottoglottica, la pressione sopraglottica e l’impedenza glottica. I valori di questi parametri si modificano durante un ciclo vibratorio in relazione all’apertura e alla chiusura della glottide ma queste rapide variazioni per motivi tecnici non possono essere normalmente misurate nel vivente. Con finalità cliniche di solito si fa riferimento ai valori medi di questi parametri che sono fra loro correlati nel modo seguente 18: Psub (pressione sottoglottica media) – Psup (pressione sopraglottica media) = MFR (quoziente medio di flusso, correlabile con la velocità) x GR (resistenza glottica media). Grazie all’utilizzo di appropriato strumentario (in alcuni casi è sufficiente un semplice cronometro), si possono ricavare utili informazioni sull’efficienza pneumo- fonatoria. Il più semplice parametro aerodinamico della voce è il tempo massimo fonatorio (MPT) espresso in secondi. Esso consiste nel far pronunciare al paziente la vocale /a/ il più a lungo possibile, dopo una profonda inspirazione, ad una frequenza ed intensità spontanee e confortevoli. È maggiore nel maschio rispetto alla femmina ma il limite critico inferiore non è molto diverso fra i due sessi: un valore inferiore a 10 secondi deve essere considerato patologico. Eventuali possibili risultati inattendibili possono verificarsi per una scarsa capacità vitale (CV) che può determinare valori ridotti pur in presenza di competenza glottica normale o per una CV molto elevata che potrebbe compensare e mascherare un difetto di chiusura glottica. Per ovviare a questo rischio si fa ricorso al quoziente fonatorio (PQ) che è correlato al MPT dalla seguente equazione: PQ = Capacità vitale/MPT (sec). Normali valori di PQ sono stati riportati da vari Autori; i valori medi nella popolazione adulta sembrano essere compresi tra 120 e 190 ml/sec. Un altro indice importante è il quoziente medio di flusso (MFR) che si ottiene dividendo la quantità di aria usata durante la fonazione per la durata della fonazione stessa. Si fa pronunciare la vocale /a/ sostenuta emessa alla naturale frequenza ed intensità utilizzata dal soggetto in esame il quale deve fonare dentro una maschera o un boccaglio con il naso pinzato connessi ad uno spirometro o ad uno pneumotacografo o ad un anemometro a filo caldo. I limiti critici sono rispettivamente 40 e 200 ml/sec per cui vanno ritenuti patologici valori non compresi in questo range. A volte può essere utile utilizzando uno spirometro per valutare la curva flussovolume che assume una importanza particolare in quei casi in cui i problemi di voce sono associati ad ostruzione laringea, come nella paralisi bilaterale adduttoria, nelle stenosi causate da cicatrici, nell’edema di Reinke di grado severo o nelle neoplasie ostruenti.La pressione aerea sottoglottica può essere misurata mediante palloncini endoesofagei, cateteri transglottici o tramite puntura tracheale; è quindi sempre una metodicainvasiva che non viene utilizzata routinariamente ma è riservata alla ricerca. Nella maggior parte dei casi i valori della pressione sottoglottica durante la fonazione normale oscillano tra i 5 e i 10 cm H2O 18. Essa è direttamente correlata all’intensità e alla frequenza di fonazione (aumenta con l’incremento di questi due parametri). Nell’ambito della patologia, sono stati riscontrati valori generalmente più alti di pressione sottoglottica in caso di carcinoma laringeo, paralisi ricorrenziale, laringocele e disfonia disfunzionale. La pressione aerea sottoglottica può infine essere utilizzata per stimare l’efficienza fonatoria. La resistenza glottica non può essere misurata direttamente, ma solo attraverso il rapporto Psub/MFR. Isshiki 20 ha riportato valori di resistenza glottica di 20-100 dyne sec/cm2 alle basse e medie frequenze e valori di 150 dyne sec/cm2 alle alte frequenze ma ulteriori ricerche sono necessarie prima dell’applicazione clinica. Fra tutti questi indici aerodinamici i più utilizzati sono il tempo massimo fonatorio (MPT) ed il quoziente fonatorio (PQ) che sono facilmente rilevabili senza la necessità di ricorrere ad apparecchiature sofisticate e/o a manovre invasive e sono in grado di fornire utili informazioni sulla efficienza glottica.
-
Categoria: Esami
-
Pubblicato: Mercoledì, 28 Marzo 2012 05:17
-
Visite: 40904
-
Stampa
-
Email
Attualmente le strumentazioni a tecnologia digitale, implementate su Personal Computer, consentono elaborazioni ed analisi del segnale verbale in modo rapido ed affidabile, offrendo nel contempo prodotti grafici e dati numerici obbiettivi prima impensabili con le apparecchiature analogiche. Una stazione di lavoro per l’analisi acustica della voce è essenzialmente costituita da un PC dotato di pacchetti software dedicati e di un hardware finalizzato all’acquisizione e riproduzione del segnale. Recentemente anche quest’ultimo può essere sostituito da una comune scheda audio incorporata nel personal computer (vedi cap. IV.5). La facilità di impiego dei diversi software e l’abbattimento dei costi hanno consentito da un lato una notevole semplificazione dell’interazione utente-macchina, dall’altro una considerevole diffusione di tali strumentazioni, per cui molti ambulatori dedicati alla diagnosi-terapia dei disturbi della voce possono disporre attualmente di sistemi di analisi acustica in grado di integrare altre valutazioni, come quella laringostroboscopica. Le principali analisi effettuate nella prassi ambulatoriale sono l’esame spettrografico a finestra lunga e corta; la determinazione della frequenza fondamentale (fo) e dell’ampiezza di emissione vocale, con il loro andamento nel tempo (curva di intonazione e di intensità); l’estrazione di parametri numerici volti all’obbiettivazione delle perturbazioni del Periodo Fondamentale (Jitter) e dell’Ampiezza (Shimmer), lo studio del bilancio energetico spettrale (rapporto fra componente periodica ed aperiodica nel segnale: Harmonic to Noise Ratio), della diplofonia (semplice o multipla) nonché degli arresti momentanei dell’emissione (Breaks Vocali). Altra metodica di analisi, nata per lo studio della voce cantata, è rappresentata dalla fonetografia, che oggi consente valutazioni del campo vocale anche in soggetti privi di «orecchio musicale» (con modalità automatica). Utilizzando come base il sistema CSL della Kay Elemetrics Corp., oggi ampiamente diffuso a livello nazionale ed internazionale (ed a cui si riferisce tutta l’iconografia presentata), si possono implementare pacchetti applicativi diversi che consentono di ottenere le misurazioni sopra riportate in modo semplice e rapido.ù
ANALISI SPETTROGRAFICA Lo spettrogramma rappresenta le variazioni temporali del contenuto spettrale del segnale verbale. Applicando a successive «finestre di analisi» la trasformata rapida di Fourier (FFT: Fast Fourier Transform) si ottiene una serie di spettri di potenza (o sezioni) che avanza nel tempo. Le informazioni di ciascuna sezione, rappresentata da frequenza ed ampiezza di ogni armonica, sono riportate rispettivamente in ordinata ed in numero di pixel di ogni piccola porzione dello schermo, codificando l’intensità con diverse variazioni colorimetriche. Il tempo viene invece rappresentato sull’asse delle ascisse come evento spettrale delle successive finestre analizzate. Lo spettrogramma è quindi una rappresentazione grafica tridimensionale che, rispetto ad altre analisi, aggiunge il pregio della temporalità; non è una analisi statica, ma rileva le modificazioni nel tempo dell’emissione glottica e del filtro sovraglottico. Questo aspetto può essere evidenziato anche in tempo reale (con l’utilizzo del software Real-time Spectrogram) con indubbi vantaggi nella pratica diagnostica e riabilitativa. La risoluzione frequenziale, che nel vecchio linguaggio analogico si risolveva in «filtro a banda larga» (banda passante sui 300 Hz) e «filtro a banda stretta» (banda passante sui 45 Hz), è ora espressa come finestra di analisi (o frame), ovvero come segmento temporale costituito da un determinato numero di campioni (o cosiddetti punti campionati). Una «finestra lunga» presenta una maggiore risoluzione frequenziale:
essa è in grado di separare le diverse armoniche e corrisponde ad un filtro analogico a banda stretta; una «finestra corta» ha minor capacità di risoluzione frequenziale: nella sua applicazione algoritmica può comprendere due o più armoniche ed è analoga ad un filtro a banda larga (Fig. 1).
È necessario dunque «presettare» la lunghezza della finestra di analisi quando ci si accinge allo studio spettrografico. Nel sistema CSL la larghezza della finestra è calcolata in numero di punti campionati. Vengono proposti nove valori: 50, 75, 100, 125, 200, 256, 512, 600 e 1024.
Il programma emula una determinata banda passante (analoga ad un filtro analogico), modificando la frequenza di campionamento e la larghezza della finestra di analisi.
Ad esempio, per dati campionati a 10.000 Hz, una finestra di 50 punti corrisponde ad una banda di 293 Hz (come una banda larga), mentre alla stessa frequenza di campionamento una finestra di analisi di 512 punti emula un filtro analogico di 29 Hz, in grado di separare ogni singola armonica anche con segnali a bassa fo. L’analisi spettrografica rappresenta uno degli esami fondamentali nello studio delle disfonie. L’interpretazione degli spettrogrammi, particolarmente quelli a finestra lunga, tiene conto della presenza ed estensione frequenziale delle armoniche, del loro andamento nel tempo, delle caratteristiche di attacco e di estinzione, della presenza o meno di diplofonia, oppure di aperiodicità (rumore) nelle diverse regioni spettrali, sostitutiva o meno della tessitura armonica. La presenza di rumore alle alte frequenze è messa in relazione con l’insufficiente tensione e adduzione cordale, con conseguente fuga d’aria fonatoria e sensazione percettiva di voce soffiata. La componente aperiodica a bassa frequenza, frammista o sostitutiva delle armoniche, è dovuta alla vibrazione irregolare per aumento dell’adduzione e della rigidità cordale.
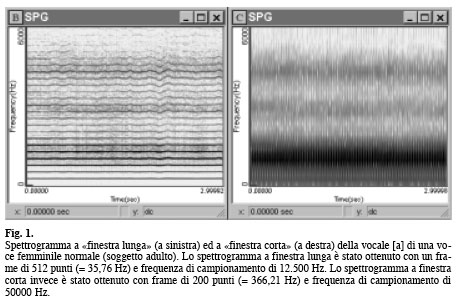
Lo spettrogramma a finestra corta fornisce un maggior numero di informazioni sulle caratteristiche di risonanza del condotto vocale, con possibilità di ricavare notizie su come il soggetto utilizza i propri organi articolatori. Considerando sia la distribuzione spettrale sia l’intensità della componente aperiodica (rumore) sia le modificazioni delle armoniche, Yanagihara (1967) ha proposto una classificazione spettrografica di gravità della disfonia. Lo studio interessava 167 pazienti che percettivamente presentavano disfonia lieve, moderata o grave: Tipo I: le regolari componenti armoniche sono frammiste alla componente di rumore nella regione formantica delle vocali [a], [i], [u], [o] ed [e] (al di sotto dei 3000 Hz): disfonia lieve. Tipo II: la componente di rumore nella seconda formante di [i] ed [e] predomina sulla componente armonica, e compare lieve rumore anche alle frequenze al di sopra dei 3000 Hz, sempre nelle stesse vocali ([i] ed [e]): disfonia moderata. Tipo III: la seconda formante di [i] ed [e] è totalmente sostituita da rumore, che aumenta ulteriormente al di sopra dei 3000 Hz: disfonia grave. Tipo IV: le seconde formanti di [a], [i] ed [e] sono sostituite da rumore, le prime formanti di tutte le vocali perdono la loro componente periodica; il rumore alle alte frequenze aumenta di intensità: disfonia molto grave. Nell’interpretazione dello spettrogramma bisogna considerare, come già sottolineato, la presenza o meno di diplofonia, che graficamente si presenta come subarmoniche di intensità ridotta intercalate alle armoniche regolari.
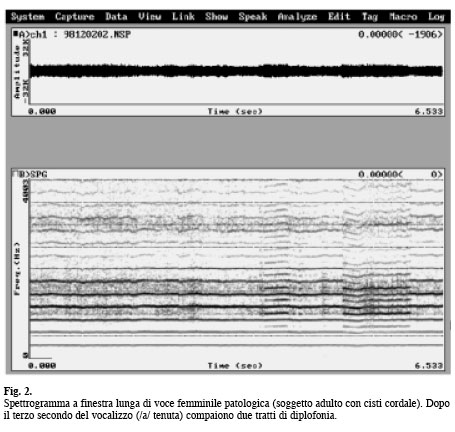
La «diplofonia» consiste in un suono laringeo complesso a cui si sovrappone un secondo suono complesso, con la seconda fondamentale subarmonica della prima, più grave di un’ottava . La diplofonia viene prodotta da una vibrazione glottica di ampiezza asimmetrica: dopo una vibrazione di una certa ampiezza ne segue una meno ampia. Non si ha la percezione di due suoni distinti, dal momento che il suono è armonico e favorisce il raggruppamento delle armoniche rispetto alla fondamentale bassa (Fig. 2). Queste caratteristiche definiscono la diplofonia di primo grado. La diplofonia di secondo grado è invece caratterizzata da una vibrazione di ampiezza ridotta ogni due vibrazioni regolari; ne consegue che la seconda fondamentale ha frequenza 1/3 rispetto alla prima e tra le armoniche del primo suono sono presenti due sub-armoniche relative al secondo suono. La diplofonia deve essere distinta dalla voce bitonale; in questo caso sono presenti due frequenze fondamentali, che possono anche non essere in rapporto armonico tra loro, poiché il secondo suono è prodotto da un’altra sorgente sonora laringea in aggiunta alla normale sorgente glottica. La seconda sorgente può essere rappresentata dalla vibrazione delle false corde o delle aritenoidi (Fig. 3).

Situazione del tutto diversa è la voce difonica, la cui genesi è riconducibile all’azione di filtraggio selettivo operata dal tratto vocale sul suono glottico. La sorgente sonora è in questo caso unica (la glottide) e produce un suono complesso normale.
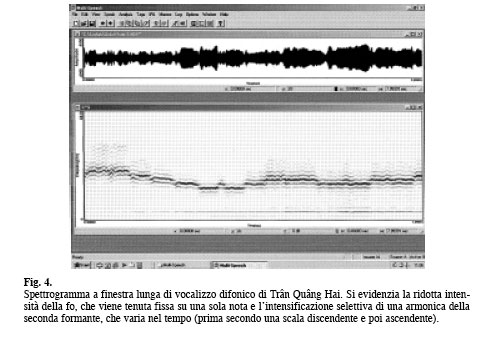
Grazie a una particolare conformazione del tratto vocale ed ad un preciso accordo fono-articolatorio, una armonica della seconda formante viene esaltata a scapito di quelle contigue, al punto da renderla percepibile come un secondo suono «puro». Il «canto difonico» rappresenta quindi il massimo effetto dell’azione di filtraggio del segnale glottico operato dal tratto vocale. L’effetto di risonanza del tratto vocale sopraglottico è appunto quello di aumentare l’ampiezza di alcune armoniche filtrandone altre; se l’inviluppo spettrale del segnale glottico si presenta monotonamente discendente senza minimi o massimi apprezzabili, il segnale verbale evidenzia picchi o zone a massima energia, denominate Formanti (F1, F2, F3, F4, ecc.) . Le Formanti rappresentano le frequenze di risonanza del condotto vocale. Lo studio delle loro caratteristiche (frequenza, ampiezza e banda), come già ricordato, consente dunque una valutazione di come il soggetto utilizza le proprie cavità sovraglottiche. La metodica utilizzata nella caratterizzazione delle formanti è l’LPC (Linear Predictive Coding) che, a partire dal segnale verbale e mediante opportune operazioni matematiche, emula le caratteristiche di quel filtro complesso e variabile nel tempo costituito dal condotto vocale. Mediante il sistema CSL 4300 B è possibile da un lato rilevare l’andamento delle frequenze formantiche sovrapposto allo spettrogramma a finestra corta e dall’altro ottenere i dati numerici relativi (Fig. 5). Le problematiche inerenti l’utilizzo dell’LPC sono state esaurientemente discusse inmletteratura ed a questa si rimanda.
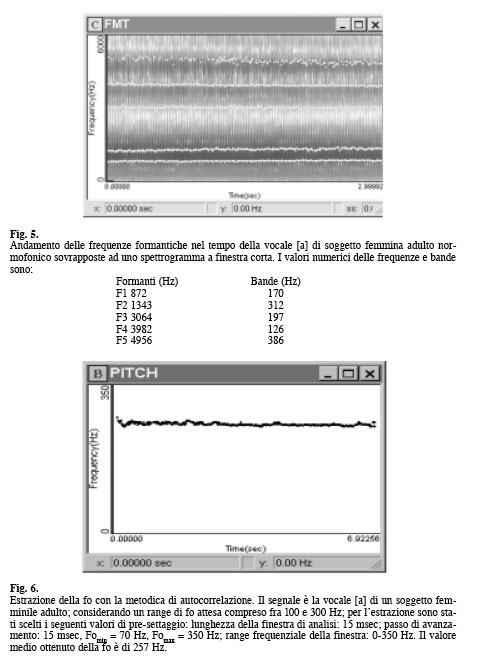
DETERMINAZIONE DELLA FREQUENZA FONDAMENTALE È effettuata dai sistemi in commercio con modalità automatica utilizzando diverse metodiche ed algoritmi a precisione variabile. La natura quasi periodica degli impulsi generati dalla laringe, e le successive modificazioni apportate dalla risonanza del condotto vocale, possono infatti creare difficoltà nell’estrarre la Frequenza Fondamentale del segnale. Nel segmento temporale considerato come intervallo di analisi (finestra di analisi), è possibile talvolta identificare due Periodi Fondamentali (e quindi due fo) diversi. Nel sistema CSL l’fo è calcolata con una metodica di autocorrelazione la quale considera come più attendibile quel valore che meglio si correla con i parametri estratti nei frames precedenti e successivi. Al fine di ridurre la possibilità di errore è indispensabile «presettare» alcune variabili di calcolo quali la lunghezza della finestra di analisi, il passo di avanzamento della finestra, i valori minimi e massimi della fo attesa (Fig. 6). In ambito clinico l’estrazione della frequenza fondamentale (fo), il suo valore numerico medio e il suo andamento nel tempo (curva di intonazione), sono importanti prodotti dell’analisi acustica, utili ai fini diagnostici e riabilitativi. Il valore numerico medio può rientrare o meno nei range di normalità di un soggetto maschio adulto, di una femmina adulta o di un bambino; la rappresentazione grafica della fo nella dimensione temporale può dare informazioni sulla tenuta, sulla presenza di diplofonia, su modificazioni di rilievo del vocalizzo.
DETERMINAZIONE DELL’AMPIEZZA
La misurazione dell’Ampiezza di un segnale complesso qual è quello verbale necessita di metodiche che si basano sui valori mediati delle ampiezze istantanee. Generalmente è utilizzata l’ampiezza efficace (in inglese RMS amplitude: root mean squared amplitude), cioè la radice quadrata della media dei quadrati delle ampiezza istantanee. Il sistema CSL agisce sui valori di ampiezza dei campioni di dati di finestre di analisi successive, e la lunghezza di queste condiziona la sensibilità dell’algoritmo. Quanto più lunga è la finestra di analisi tanto minore è la sensibilità alle rapide variazioni di ampiezza che nel tracciato appariranno «addolcite» (in inglese «smoothed»). Per ovviare a tali problemi di calcolo lo stesso sistema utilizza una lunghezza di finestra uguale ad ogni periodo della forma d’onda. La lunghezza della finestra è dunque variabile avendo ogni volta il valore del Periodo Fondamentale misurato. La metodica è definita «pitch-synchronous». Se invece è preselezionata una determinata lunghezza (i valori possibili nel sistema CSL operante in ambiente Windows variano da 1 a 250 msec) l’estrazione dell’energia sarà «pitch asynchronous». L’estrazione dell’energia o ampiezza, particolarmente nella sua rappresentazione grafica (curva di intensità) fornisce informazioni sull’attacco vocale (dolce o duro) e sulla tenuta di emissione (regolare, irregolare, modulata, interrotta, in caduta, insufficiente) (Fig. 7).
Il software Real-Time Pitch Extraction, supportato dal sistema CSL, fornisce in tempo reale il grafico dell’andamento della fo e dell’ampiezza, ed in tempo differito i valori statistici relativi. Il suo utilizzo riveste importanza, oltre che diagnostica, soprattutto riabilitativa poiché costituisce un modello target nel trattamento dei disturbi della voce.
PARAMETRI DI VOCALITÀ
Il segnale vocale è un suono complesso quasi periodico, presenta cioè, anche se prodotto con la massima stazionarietà e da un soggetto normofonico, variazioni del Periodo Fondamentale e dell’Ampiezza, a breve e/o a lungo termine. Le modificazioni casuali a breve termine (microperturbazioni) del Periodo Fondamentale, e quindi della fo, sono definite come jitter, mentre quelle dell’Ampiezza come shimmer.
Le variazioni regolari delle stesse caratteristiche del segnale a lungo termine (più o meno periodiche) costituiscono al contrario le così dette modulazioni di Frequenza ed Ampiezza (tremori di Frequenza ed Ampiezza) e di esse è calcolabile sia la frequenza che la profondità. Oltre a questi parametri è stato poi introdotto anche il rapporto fra energia armonica e disarmonica (HNR: Harmonic to Noise Ratio) o il suo «inverso» (NHR: Noise to Harmonic Ratio), la quantificazione della diplofonia semplice o multipla, la misurazione delle interruzioni momentanee o irregolari dell’emissione. Il software MDVP (Multi-Dimensional Voice Program), supportato dal sistema CSL, con frequenza di campionamento di 25000 o 50000 Hz di una emissione, per default, di tre secondi (in genere una [a]), calcola tutti questi parametri offrendo nel contempo rappresentazioni grafiche originali. L’algoritmo di calcolo del jitter e shimmer effettua una media delle differenze di durata o ampiezza di periodi successivi adiacenti; il risultato può essere espresso in valore assoluto (jitter in μs: Jita, shimmer in dB: ShdB) o in percentuale (%) dividendo rispettivamente i valori assoluti per il valore medio del Periodo Fondamentale e dell’Ampiezza (Jitt e Shim nel sistema MDVP). Altri parametri che esplorano le stesse caratteristiche sono ottenuti mediante sotto-medie di periodi adiacenti (3, 5, 11 o altri valori definibili dall’utente), e ciò al fine di ridurre l’errore dovuto ad inadeguata estrazione del Periodo Fondamentale. Ne derivano, in percentuale, i parametri RAP (Perturbazione Relativa Media: Relative Average Perturbation), PPQ (Quoziente di Perturbazione di fo: Pitch Period Perturbation Quotient), sPPQ (Quoziente Mediato di Perturbazione di fo: Smoothed Pitch Period Perturbation Quotient) per il jitter, ed i parametri APQ (Quoziente di Perturbazione di Ampiezza:
Amplitude Perturbation Quotient), sAPQ (Quoziente Mediato di Perturbazione di Ampiezza: Smoothed Amplitude Perturbation Quotient) per il shimmer. Le modulazioni di Frequenza ed Ampiezza, nelle loro caratteristiche di frequenza ed ampiezza (o profondità), sono espresse, per la frequenza (in Hz), dai parametri Fftr (Frequenza del tremore della Fo: Fo – Tremor Frequency) e Fatr (Frequenza del tremore in ampiezza: Amplitude Tremor Frequency) e, per la profondità (in %), dai parametri FTRI (Indice di profondità del tremore in frequenza: Frequency Tremor Intensity Index) ed ATRI (Indice di profondità del tremore in ampiezza:
Amplitude Tremor Intensity Index). Le variazioni percentuali complessive a breve ed a lungo termine, casuali o regolari, sono rilevate per la frequenza dal parametro vFo (Variazione di Fo: Fundamental Frequency Variation) e per l’ampiezza da vAm (Variazione di Ampiezza di Picco: Peak Amplitude Variation), calcolate rispettivamente dal rapporto fra la deviazione standard ed il valore medio della fo e dell’Ampiezza. I bilanci energetici spettrali in diversi range frequenziali sono espressi, in valore assoluto, mediante i parametri:
• NHR (Rapporto Rumore-Armoniche: Noise to Harmonic Ratio): rapporto medio di energia fra le componenti disarmoniche (rumore) nella banda 1500- 4500 Hz e le componenti armoniche nella banda 70-4500 Hz. • VTI (Indice di Turbolenza: Voice Turbulence Index): rapporto medio fra le componenti di energia spettrale disarmonica (di rumore) nella banda 2800- 5800 Hz e le componenti di energia spettrale armonica nella banda 70-4500 Hz. Il parametro dovrebbe essere altamente correlato con la turbolenza secondaria ad incompleta o lenta adduzione delle corde vocali, cioè con la voce definita «soffiata». • SPI (Indice di Fonazione Sommessa: Soft Phonation Index): rapporto medio fra l’energia spettrale armonica nella banda 70-1600 Hz, e l’energia spettrale armonica nella banda 1600-4500 Hz. Questo parametro non è una misura del livello di rumore, ma piuttosto della struttura armonica dello spettro. I rimanenti parametri sono relativi alla obbiettivazione della diplofonia (DSH in % o grado di diplofonia: Degree of sub-harmonic components, ed NSH in valore assoluto o numero di segmenti diplofonici: Number of Sub-Harmonic Segments), delle interruzioni momentanee della sonorità (DVB in % o grado di rotture della sonorità: Degree of Voice Breaks, ed NVB in numero assoluto o numero di rotture della sonorità: Number of Voice Breaks), e degli arresti irregolari della sonorità (DUV in % o grado di sordità: Degree of Voiceless, ed NUV in numero assoluto o numero di segmenti sordi: Number of Unvoiced Segments). Il valore normativo di questi è per definizione uguale a zero in quanto una voce normale sostenuta non dovrebbe avere zone di interruzione né segmenti diplofonici. L’MDVP fornisce due videate grafiche di cui una consente di valutare «a vista» i valori parametrici in soglia o che eccedono la normalità, costituendo per l’otorinofoniatra quello che l’audiogramma è per l’audiologo, ed a ben ragione è dunque definito «vocaligramma» (Fig. 8). L’utilizzo di questi parametri offre la possibilità di disporre di dati oggettivi in grado di caratterizzare una determinata disfunzione vocale. In particolare permette la integrazione con quella soggettività insita non solo nella valutazione uditivo-percettiva della voce, ma anche nella stessa valutazione spettrografica. Infatti anche in quest’ultima l’interpretazione si basa prevalentemente su una impressione visiva che condiziona un giudizio ampiamente soggettivo. Disporre di una vasta gamma di parametri di vocalità, come sopra elencato, può risultare clinicamente utile in quanto alcuni di questi possono essere caratterizzanti per una certa patologia. Ad esempio una voce soffiata può avere i parametri relativi alle perturbazioni a breve termine nella norma, e valori dei parametri relativi alla turbolenza anomali.

Così pure i parametri relativi al tremore che misurano l’instabilità della voce a lungo termine possono risultare patologici in pazienti affetti da morbo di Parkinson e normali in altre patologie laringee. D’altra parte molti dei parametri elencati sono certamente ridondanti poiché esprimono, con algoritmi diversi, una identica caratteristica vocale. Numerose ricerche da un lato suggeriscono di ridurre i parametri MDVP convenzionalmente utilizzabili a soli undici (Fig. 9) e dall’altro sottolineano la opportunità che ogni laboratorio si attrezzi di una propria normativa. Infatti, a parità di utilizzo del medesimo sistema di analisi, ogni gruppo di lavoro può presentare modalità assai diverse sia per la registrazione, le situazioni di rumore ambientale, i microfoni … etc. Questi fattori, insieme alla diversa tipologia della popolazione considerata e al diverso giudizio di qualità vocale, possono determinare con relativa facilità variazioni non trascurabili della soglia di normalità e quindi della categorizzazione nosologica del soggetto. Presenteremo ora alcuni esempi clinici. Caso 1: soggetto di sesso femminile, età 37 anni, normofonico. In Figura 10, nelle diverse finestre, sono rappresentati: A: forma d’onda dellavocale [a] sostenuta; B: spettrogramma a finestra lunga di analisi; C: andamento della fo e dell’intensità nel tempo; D: vocaligramma. Si noti la regolare tenuta sia dell’intensità che della Frequenza Fondamentale e la regolarità delle armoniche nello spettrogramma; in quest’ultimo tuttavia si può intravedere energia disarmonica (rumore) a bassa intensità, intercalata alla tessitura armonica e non sostitutiva.
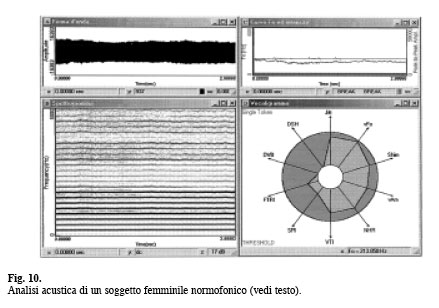
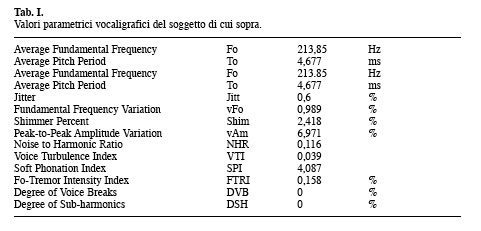
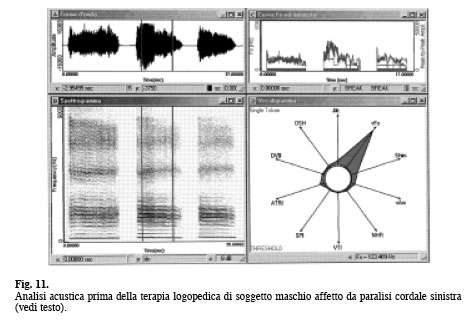
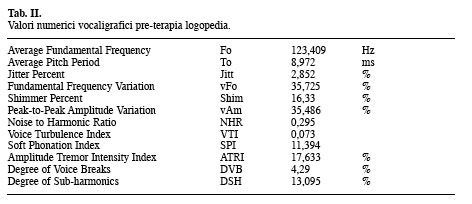
Il vocaligramma evidenzia tutti gli indici di vocalità entro i limiti normativi. Il parametro ATRI, relativo alla profondità delle modulazioni di Ampiezza, non è graficato in quanto il suo valore è inferiore alla soglia di analisi del sistema che per default è 4,37%. In Tabella I sono riportati i valori degli indici vocaligrafici. Caso 2: maschio di 27 anni affetto da paralisi cordale sinistra post-tiroidectomia con inadeguato compenso cordale controlaterale. Analisi acustica prima della terapia logopedica. Nella finestra A della Figura 11 sono riportate le forme d’onda di tre [a] sostenute; la porzione di forma d’onda della terza [a], delimitata dai cursori in blu (circa tre secondi), rappresenta la parte del segnale sottoposto ad analisi multiparametrica con il sistema MDVP e la cui rappresentazione grafica è riportata nella finestra D. La finestra B evidenzia lo spettrogramma relativo con scarsa rappresentazione della tessitura armonica, presenza di rumore intercalato alle armoniche alle basse frequenze e completamente sostitutivo alle medio-alte (grado tre sec. Yanagihara). Si intravede inoltre diplofonia, soprattutto nella seconda e terza [a]. Nella stessa finestra sono riportati i cursori (in blu) che delimitano la porzione di spettrogramma corrispondente alla parte della forma d’onda analizzata con il sistema MDVP. La corrispondenza è ottenuta mediante il comando «Link Windows …» del menù. Questa modalità di analisi è importante in quanto consente di controllare i dati spettrografici con l’analisi obbiettiva multiparametrica. Si noti inoltre la scarsa tenuta della fo e dell’intensità. In Tabella II sono riportati i valori numerici vocaligrafici relativi.
Il paziente ha seguito riabilitazione logopedica (dodici sedute) ottenendo una completa chiusura glottica fonatoria; persiste tuttavia la paralisi cordale sinistra. All’analisi acustica di tre [a] sostenute e consecutive (Fig. 12), si rileva un ripristino della tessitura armonica anche alle alte frequenze con intercalato rumore parzialmente sostitutivo alle alte frequenze; non si evidenzia diplofonia. La valutazione mediante MDVP è stata effettuata con la stessa modalità di cui sopra, ossia delimitando una porzione di forma d’onda di circa tre secondi con controllo visivo dello spettrogramma corrispondente. Il vocaligramma riporta una riduzione significativa di molti dei parametri che prima della terapia eccedevano la normalità. Persiste un aumento lieve dello Shim e maggiormente del parametro VTI, indice di rumore alle più alte frequenze. In Tabella III i valori numerici relativi.
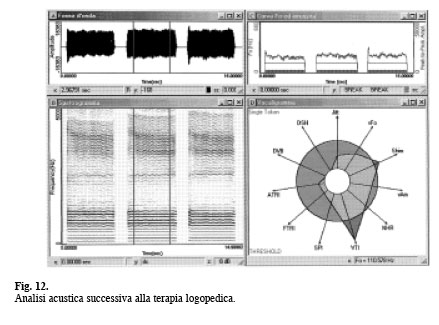
FONETOGRAFIA La metodica rappresenta graficamente e misura l’intensità minima e massima di emissione vocale alle diverse frequenze, dalle più gravi alle più acute. È dunque una rappresentazione dell’entità del campo vocale del soggetto. In ascissa è riportata la frequenza ed in ordinata l’intensità; il grafico risultante (Fonetogramma) è essenzialmente costituito da due linee: la cosiddetta «curva dei piani» che rappresenta l’estensione vocale alle più deboli intensità, e la «curva dei forti» che indica l’estensione alle intensità più elevate. Operativamente, ad esempio mediante una tastiera sonora, viene prodotto un suono che il soggetto deve riprodurre alla massima e minima intensità; se l’altezza del vocalizzo eseguito corrisponde a quella richiesta dall’esaminatore, l’intensità rilevata con un fonometro, posizionato a 30 cm dalla bocca, è riportata sul grafico in corrispondenza della frequenza fondamentale emessa. Una tale modalità può essere lunga e laboriosa, poiché richiede da parte dell’esaminando e dell’esaminatore un «orecchio musicale». Queste difficoltà sono attualmente superabili con metodi informatici che utilizzano softwares che consentono la rilevazione del campo vocale anche in soggetti «stonati», richiedendo l’esecuzione alla massima e alla minima intensità di una scala musicale o di una «sirena», che dalla nota più grave arriva fino a quella più acuta. Nelle figure seguenti (Figg. 13 e 14) sono esemplificati i campi vocali ottenuti con metodica tradizionale (Restricted plot to target tone) e con metodica di registrazione di tutte le emissioni del soggetto testato (Plot all input), utilizzando il software Voice Range Profile (VRP) Model 4.326 della Kay Elemetrics Corp.
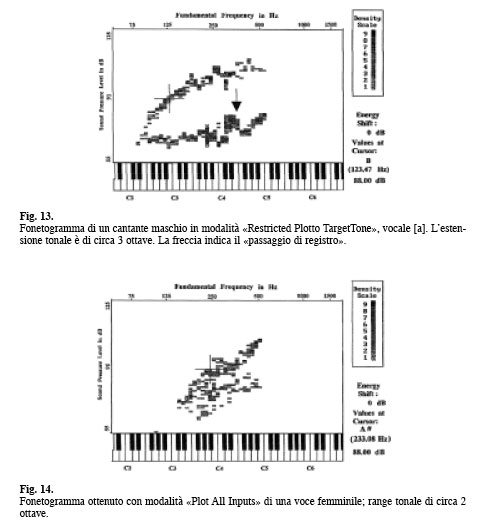
Il range tonale nei soggetti normali è di almeno due ottave (24 note successive o «semitoni»); esso può aumentare fino a tre ottave nei cantanti professionisti e può ridursi a pochi semitoni in caso di patologia laringea. La dinamica della intensità è massima nelle note centrali dell’estensione tonale e si riduce sia verso le note più gravi sia verso le più acute. I più importanti parametri di valutazione sono: a) il range in semitoni; b) la massima frequenza; c) la minima intensità; d) la riduzione di dinamica in intensità che si può osservare nella nota del «passaggio di registro» (Fig. 13) (I). La fonetografia ha una notevole importanza nella classificazione della voce cantata e nella diagnosi delle disodie, ma attualmente si assiste ad una sua sempre maggiore applicazione anche nella diagnostica e nel follow-up delle disfonie. Con la combinazione di diversi parametri acustici Wuyts et al. (IV) hanno proposto un indice caratterizzante la gravità della disfonia (Dysphonia Severity Index – Indice di Severità della Disfonia). I parametri acustici utilizzati sono il Tempo Fonatorio Massimo in sec. (MPT), la massima frequenza in Hz (Fo – High), la minima intensità in dB (I – Low) e il Jitter in %. I valori di massima frequenza e minima intensità sono ottenuti dal fonetogramma, mentre il valore del Jitter viene ottenuto dal grafico dell’MDVP. Mediante un’analisi discriminativa lineare di Fisher gli AA definiscono la seguente formula: DSH = 0,13 x TMF + 0,0053 x Fo max – 0,26 x I min – 1,18 x Jitter % + 12,4 Una voce normale ottiene valori di DSI intorno a + 5, mentre una disfonia lieve (G1) corrisponde ad un DSI di + 1, una disfonia moderata (G2) corrisponde ad un DSI di - 1,4 ed una disfonia grave (G3) corrisponde ad un DSI di - 5. Secondo l’esperienza degli Autori, eventuali artefatti o irregolarità nel calcolo del DSI possono avvenire soprattutto se non viene valutato accuratamente il valore della minima intensità nel fonetogramma. Questa metodica merita di essere presa in considerazione nella batteria delle indagini per la valutazione della voce, anche se necessita di essere sperimentata da vari operatori del settore per la sua validazione definitiva.


 CONCLUSIONI
CONCLUSIONI





